Data Analyst Role Play: Profiling and Analyzing the Yelp Dataset
Part 1: Yelp Dataset Profiling and Understanding
Part 1: In the first part, a series of questions that profile and provide understanding of the data will be answered; just like a data scientist would.
Yelp Dataset ER Diagram
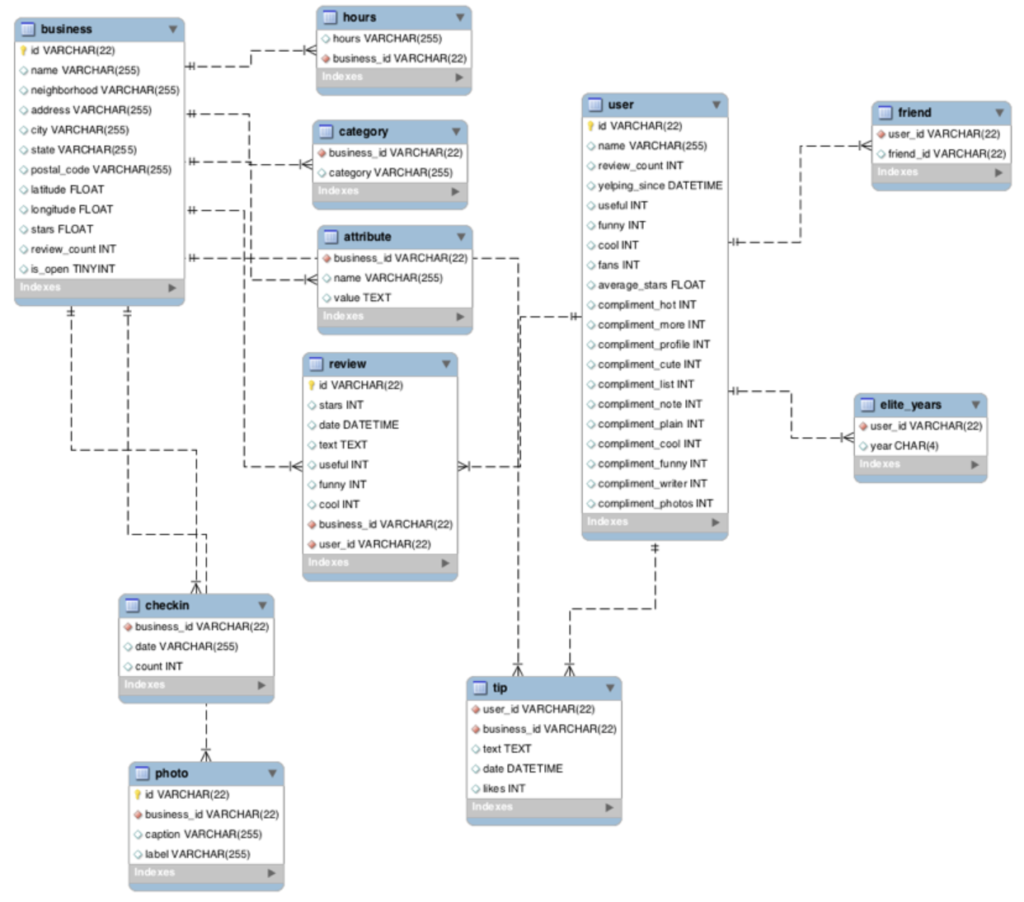
Note: Primary Keys are denoted in the ER-Diagram with a yellow key icon.
1) Profile the data by finding the total number of records for each of the tables below:
#i. Attribute table =
SELECT COUNT(*) AS TotalAttributes FROM attribute;
+-----------------+
| TotalAttributes |
+-----------------+
| 10000 |
+-----------------+
#ii. Business table =
SELECT COUNT(*) AS TotalBusiness FROM business;
+---------------+
| TotalBusiness |
+---------------+
| 10000 |
+---------------+
#iii. Category table =
SELECT COUNT(*) AS TotalCategory FROM category;
+---------------+
| TotalCategory |
+---------------+
| 10000 |
+---------------+
#iv. Checkin table =
SELECT COUNT(*) AS TotalCheckIn FROM checkin;
+--------------+
| TotalCheckIn |
+--------------+
| 10000 |
+--------------+
#v. elite_years table =
SELECT COUNT(*) AS TotalElite_Years FROM elite_years;
+------------------+
| TotalElite_Years |
+------------------+
| 10000 |
+------------------+
#vi. friend table =
SELECT COUNT(*) AS TotalFriend FROM friend;
+-------------+
| TotalFriend |
+-------------+
| 10000 |
+-------------+
#vii. hours table =
SELECT COUNT(*) AS TotalHours FROM hours;
+------------+
| TotalHours |
+------------+
| 10000 |
+------------+
#viii. photo table =
SELECT COUNT(*) AS TotalPhoto FROM photo;
+------------+
| TotalPhoto |
+------------+
| 10000 |
+------------+
#ix. review table =
SELECT COUNT(*) AS TotalReview FROM review;
+-------------+
| TotalReview |
+-------------+
| 10000 |
+-------------+
#x. tip table =
SELECT COUNT(*) AS TotalTip FROM tip;
+----------+
| TotalTip |
+----------+
| 10000 |
+----------+
#xi. user table =
SELECT COUNT(*) AS TotalUser FROM user;
+-----------+
| TotalUser |
+-----------+
| 10000 |
+-----------+2) Find the total distinct records by either the foreign key or primary key for each table. If two foreign keys are listed in the table, please specify which foreign key.
#i. Business (Primary Key: id)
SELECT COUNT(DISTINCT(id)) AS DistinctIDs
FROM business;
+-------------+
| DistinctIDs |
+-------------+
| 10000 |
+-------------+
#ii. Hours (Foreign Key: business_id)
SELECT COUNT(DISTINCT(business_id)) AS DistinctHoursBusinessId
FROM hours;
+-------------------------+
| DistinctHoursBusinessId |
+-------------------------+
| 1562 |
+-------------------------+
#iii. Category (Foreign Key: business_id)
SELECT COUNT(DISTINCT(business_id)) AS DistinctCategoryBusinessId
FROM category;
+----------------------------+
| DistinctCategoryBusinessId |
+----------------------------+
| 2643 |
+----------------------------+
#iv. Attribute (Foreign Key: business_id)
SELECT COUNT(DISTINCT(business_id)) AS DistinctAttributeBusinessId
FROM attribute;
+-----------------------------+
| DistinctAttributeBusinessId |
+-----------------------------+
| 1115 |
+-----------------------------+
#v. Review (Primary Key: id)
SELECT COUNT(DISTINCT(id)) AS DistinctReviewId
FROM review;
+------------------+
| DistinctReviewId |
+------------------+
| 10000 |
+------------------+
#vi. Checkin (Foreign Key: business_id)
SELECT COUNT(DISTINCT(business_id)) AS DistinctCheckInBusinessId
FROM checkin;
+---------------------------+
| DistinctCheckInBusinessId |
+---------------------------+
| 493 |
+---------------------------+
#vii. Photo (Primary Key: id)
SELECT COUNT(DISTINCT(id)) AS DistinctPhotoId
FROM photo;
+-----------------+
| DistinctPhotoId |
+-----------------+
| 10000 |
+-----------------+
#viii. Tip (Foreign Key: user_id)
SELECT COUNT(DISTINCT(user_id)) AS DistinctTipUserId
FROM tip;
+-------------------+
| DistinctTipUserId |
+-------------------+
| 537 |
+-------------------+
#ix. User (Primary Key: id)
SELECT COUNT(DISTINCT(id)) AS DistinctUserId
FROM user;
+----------------+
| DistinctUserId |
+----------------+
| 10000 |
+----------------+
#x. Friend (Foreign Key: user_id)
SELECT COUNT(DISTINCT(user_id)) AS DistinctFriendUserId
FROM friend;
+----------------------+
| DistinctFriendUserId |
+----------------------+
| 11 |
+----------------------+
#xi. Elite_years (Foreign Key: user_id)
SELECT COUNT(DISTINCT(user_id)) AS DistinctEliteYearsUserId
FROM elite_years;
+--------------------------+
| DistinctEliteYearsUserId |
+--------------------------+
| 2780 |
+--------------------------+3) Are there any columns with null values in the Users table? Indicate «yes,» or «no.»
#SQL code used to arrive at answer: used COUNT to count the CASE logic. When cell is NULL then it will count as 1, and this will be counted by the outer query and named with the AS statement
SELECT
COUNT(*) AS TotalRows,
COUNT(CASE WHEN id IS NULL THEN 1 END) AS NullId,
COUNT(CASE WHEN name IS NULL THEN 1 END) AS NullName,
COUNT(CASE WHEN review_count IS NULL THEN 1 END) AS NullReviewCount,
COUNT(CASE WHEN yelping_since IS NULL THEN 1 END) AS NullYelpingSince,
COUNT(CASE WHEN useful IS NULL THEN 1 END) AS NullUseful,
COUNT(CASE WHEN funny IS NULL THEN 1 END) AS NullFunny,
COUNT(CASE WHEN cool IS NULL THEN 1 END) AS NullCool,
COUNT(CASE WHEN fans IS NULL THEN 1 END) AS NullFans,
COUNT(CASE WHEN average_stars IS NULL THEN 1 END) AS NullAvgStars,
COUNT(CASE WHEN compliment_hot IS NULL THEN 1 END) AS NullHot,
COUNT(CASE WHEN compliment_more IS NULL THEN 1 END) AS NullMore,
COUNT(CASE WHEN compliment_profile IS NULL THEN 1 END) AS NullProf,
COUNT(CASE WHEN compliment_cute IS NULL THEN 1 END) AS NullCute,
COUNT(CASE WHEN compliment_list IS NULL THEN 1 END) AS NullList,
COUNT(CASE WHEN compliment_note IS NULL THEN 1 END) AS NullNote,
COUNT(CASE WHEN compliment_plain IS NULL THEN 1 END) AS NullPlain,
COUNT(CASE WHEN compliment_cool IS NULL THEN 1 END) AS NullCool,
COUNT(CASE WHEN compliment_funny IS NULL THEN 1 END) AS NullFunny,
COUNT(CASE WHEN compliment_writer IS NULL THEN 1 END) AS NullWriter,
COUNT(CASE WHEN compliment_photos IS NULL THEN 1 END) AS NullPhotos
FROM user;
--
#RESULT:
- TotalRows: 10000
- NullId: 0
- NullName: 0
- NullReviewCount: 0
- NullYelpingSince: 0
- NullUseful: 0
- NullFunny: 0
- NullCool: 0
- NullFans: 0
- NullAvgStars: 0
- NullHot: 0
- NullMore: 0
- NullProf: 0
- NullCute: 0
- NullList: 0
- NullNote: 0
- NullPlain: 0
- NullCool: 0
- NullFunny: 0
- NullWriter: 0
- NullPhotos: 0
--
#ANSWER: NO, there are no columns with NULL values in the user table.4) For each table and column listed below, display the smallest (minimum), largest (maximum), and average (mean) value for the following fields:
#SQL code used to arrive at answer, and results.
#i Table: reviews. Column: stars
SELECT MIN(stars) AS minStars, MAX(stars) AS maxStars, AVG(stars) AS avgStars
FROM Review;
+----------+----------+----------+
| minStars | maxStars | avgStars |
+----------+----------+----------+
| 1 | 5 | 3.7082 |
+----------+----------+----------+
#ii Table: business, Column: stars
SELECT MIN(stars) AS minStars, MAX(stars) AS maxStars, AVG(stars) AS avgStars
FROM business;
+----------+----------+----------+
| minStars | maxStars | avgStars |
+----------+----------+----------+
| 1.0 | 5.0 | 3.6549 |
+----------+----------+----------+
#iii Table: tip. Column: likes
SELECT MIN(likes) AS minLikes, MAX(likes) AS maxLikes, AVG(likes) AS avgLikes
FROM tip;
+----------+----------+----------+
| minLikes | maxLikes | avgLikes |
+----------+----------+----------+
| 0 | 2 | 0.0144 |
+----------+----------+----------+
#iv Table: checkin. Column: count
SELECT MIN(count) AS minCount, MAX(count) AS maxCount, AVG(count) AS avgCount
FROM checkin;
+----------+----------+----------+
| minCount | maxCount | avgCount |
+----------+----------+----------+
| 1 | 53 | 1.9414 |
+----------+----------+----------+
#v Table: user. Column: review_count
SELECT MIN(review_count) AS minReviewCount, MAX(review_count) AS maxReviewCount, AVG(review_count) AS avgReviewCount
FROM user;
+----------------+----------------+----------------+
| minReviewCount | maxReviewCount | avgReviewCount |
+----------------+----------------+----------------+
| 0 | 2000 | 24.2995 |
+----------------+----------------+----------------+5) List the cities with the most reviews in descending order:
#SQL code used to arrive at answer: Used the business and review tables. I select city from business and count id from the review table, then join then, group them so that reviews count for each city sums, and finally order them in desc as the question asked for it.
SELECT city, SUM(review_count) AS total_reviews
FROM business
GROUP BY city
ORDER BY total_reviews DESC
--ANSWER:
+-----------------+---------------+
| city | total_reviews |
+-----------------+---------------+
| Las Vegas | 82854 |
| Phoenix | 34503 |
| Toronto | 24113 |
| Scottsdale | 20614 |
| Charlotte | 12523 |
| Henderson | 10871 |
| Tempe | 10504 |
| Pittsburgh | 9798 |
| Montréal | 9448 |
| Chandler | 8112 |
| Mesa | 6875 |
| Gilbert | 6380 |
| Cleveland | 5593 |
| Madison | 5265 |
| Glendale | 4406 |
| Mississauga | 3814 |
| Edinburgh | 2792 |
| Peoria | 2624 |
| North Las Vegas | 2438 |
| Markham | 2352 |
| Champaign | 2029 |
| Stuttgart | 1849 |
| Surprise | 1520 |
| Lakewood | 1465 |
| Goodyear | 1155 |
+-----------------+---------------+
(Output limit exceeded, 25 of 362 total rows shown)6) Find the distribution of star ratings to the business in the following cities:
*Avon, Beachwood
#SQL code used to arrive at answer: Firstly I SELECTed the cities column needed in the query and counted stars to count the occurrence of each star rating. in FROM I specify that the I am using the business table. In WHERE I choose the necessary cities and in finally I use GROUP BY clause to group the results by "city".
SELECT city, stars, COUNT(stars) AS StarCount
FROM business
WHERE city = 'Avon'
GROUP BY stars;
+------+-------+-----------+
| city | stars | StarCount |
+------+-------+-----------+
| Avon | 1.5 | 1 |
| Avon | 2.5 | 2 |
| Avon | 3.5 | 3 |
| Avon | 4.0 | 2 |
| Avon | 4.5 | 1 |
| Avon | 5.0 | 1 |
+------+-------+-----------+
SELECT city, stars, COUNT(stars) AS StarCount
FROM business
WHERE city = 'Beachwood'
GROUP BY stars;
+-----------+-------+-----------+
| city | stars | StarCount |
+-----------+-------+-----------+
| Beachwood | 2.0 | 1 |
| Beachwood | 2.5 | 1 |
| Beachwood | 3.0 | 2 |
| Beachwood | 3.5 | 2 |
| Beachwood | 4.0 | 1 |
| Beachwood | 4.5 | 2 |
| Beachwood | 5.0 | 5 |
+-----------+-------+-----------+7) Find the top 3 users based on their total number of reviews:
#SQL code used to arrive at answer:
SELECT id, name, review_count
FROM user
GROUP BY id, name
ORDER BY review_count DESC
LIMIT 3;
+------------------------+--------+--------------+
| id | name | review_count |
+------------------------+--------+--------------+
| -G7Zkl1wIWBBmD0KRy_sCw | Gerald | 2000 |
| -3s52C4zL_DHRK0ULG6qtg | Sara | 1629 |
| -8lbUNlXVSoXqaRRiHiSNg | Yuri | 1339 |
+------------------------+--------+--------------+8) Does posing more reviews correlate with more fans?
#SQL code used to arrive at answer:
--Direct Solution (NO CORR function in SQlite)
SELECT id, name, review_count, fans, CORR(review_count, fans) AS CorrelationReviewFans
FROM user
GROUP BY id, name
ORDER BY review_count DESC;
--Alt solution
SELECT name, review_count, fans
FROM user
GROUP BY id, name
ORDER BY review_count DESC
LIMIT 10;
+-----------+--------------+------+
| name | review_count | fans |
+-----------+--------------+------+
| Gerald | 2000 | 253 |
| Sara | 1629 | 50 |
| Yuri | 1339 | 76 |
| .Hon | 1246 | 101 |
| William | 1215 | 126 |
| Harald | 1153 | 311 |
| eric | 1116 | 16 |
| Roanna | 1039 | 104 |
| Mimi | 968 | 497 |
| Christine | 930 | 173 |
+-----------+--------------+------+
SELECT name, review_count, fans
FROM user
GROUP BY id, name
ORDER BY review_count ASC
LIMIT 10;
+---------------+--------------+------+
| name | review_count | fans |
+---------------+--------------+------+
| Sonnenschein1 | 0 | 0 |
| svenher | 0 | 0 |
| Limon-Du | 0 | 0 |
| ab | 0 | 0 |
| Schweinefe | 0 | 0 |
| Luke | 0 | 0 |
| torstenbec | 0 | 0 |
| snek | 0 | 0 |
| ... | 0 | 0 |
| Joe | 1 | 0 |
+---------------+--------------+------+
Please explain your findings and interpretation of the results: As I couldn’t use the Correlation function I explored the limits of the “review_count” and “fans” attributes with sorting and filtering. Visually there is a correlation in review_counts and fans, as fans are considerably more when the review_count is high. But on the other side, the fans total numbers vary considerably even on high amounts of reviews. *For example,* on the results of the query we can see “eric” with 1116 review and only 16 fans. And just one row on top there is Harald, which has 1153 reviews and a very high amount of fans: 311.
With this analysis, I can say with a medium level of confidence that posing more reviews has a low to mid correlation with the amount of fans.9) Are there more reviews with the word «love» or with the word «hate» in them?
#SQL code used to arrive at answer:
SELECT
SUM(CASE WHEN text LIKE '%love%' THEN 1 ELSE 0 END) AS LoveCount,
SUM(CASE WHEN text LIKE '%hate%' THEN 1 ELSE 0 END) AS HateCount
FROM review;
+-----------+-----------+
| LoveCount | HateCount |
+-----------+-----------+
| 1780 | 232 |
+-----------+-----------+
Answer: the count of LoveCounts in the reviews is significantly higher, approximately 7.672 times, compared to the count of HateCounts.10) Find the top 10 users with the most fans:
#SQL code used to arrive at answer:
SELECT id, name, fans
FROM user
ORDER BY fans DESC
LIMIT 10;
+------------------------+-----------+------+
| id | name | fans |
+------------------------+-----------+------+
| -9I98YbNQnLdAmcYfb324Q | Amy | 503 |
| -8EnCioUmDygAbsYZmTeRQ | Mimi | 497 |
| -2vR0DIsmQ6WfcSzKWigw | Harald | 311 |
| -G7Zkl1wIWBBmD0KRy_sCw | Gerald | 253 |
| -0IiMAZI2SsQ7VmyzJjokQ | Christine | 173 |
| -g3XIcCb2b-BD0QBCcq2Sw | Lisa | 159 |
| -9bbDysuiWeo2VShFJJtcw | Cat | 133 |
| -FZBTkAZEXoP7CYvRV2ZwQ | William | 126 |
| -9da1xk7zgnnfO1uTVYGkA | Fran | 124 |
| -lh59ko3dxChBSZ9U7LfUw | Lissa | 120 |
+------------------------+-----------+------+Part 2: Inferences and Analysis
Part 2: contains inferences and analysis of the data for particular research questions.
1) Pick one city and category of your choice. Group the businesses in that city or category by their overall star rating. Compare the businesses with 2-3 stars to the businesses with 4-5 stars and answer the following questions. Include your code.
# I chose several categories starting with 'M' as there was to little available data by category in relation to cities.
SELECT *
FROM category
WHERE category LIKE 'M%'
GROUP BY category
# I chose the city 'Guadalupe' as it has 5.0 stars.
SELECT city, stars
FROM business
GROUP BY city
ORDER BY stars DESC;#a) Queried for the avg stars of business in Guadalupe.
SELECT city, AVG(stars) AS AvgStars
FROM business
WHERE city = 'Guadalupe'
GROUP BY city;
+-----------+----------+
| city | AvgStars |
+-----------+----------+
| Guadalupe | 4.5 |
+-----------+----------+
#Queried for avg stars of specific categories selected. I chose 6 to have more variety.
SELECT b.name, AVG(b.stars) AS AvgStars, c.category
FROM business b
JOIN category c ON b.id = c.business_id
WHERE c.category IN ('Massage', 'Massage Schools', 'Massage therapy', 'Medical Centers', 'Medical Spas', 'Meditation Centers')
GROUP BY b.name;
--RESULT:
Haggard Chiropractic | 5.0 | Massage
Humber River Regional Hospital | 2.0 | Medical Centers
#b) I will be comparing the two results I got from the categories chosen.
SELECT *
FROM business
WHERE name = 'Haggard Chiropractic' OR name = 'Humber River Regional Hospital';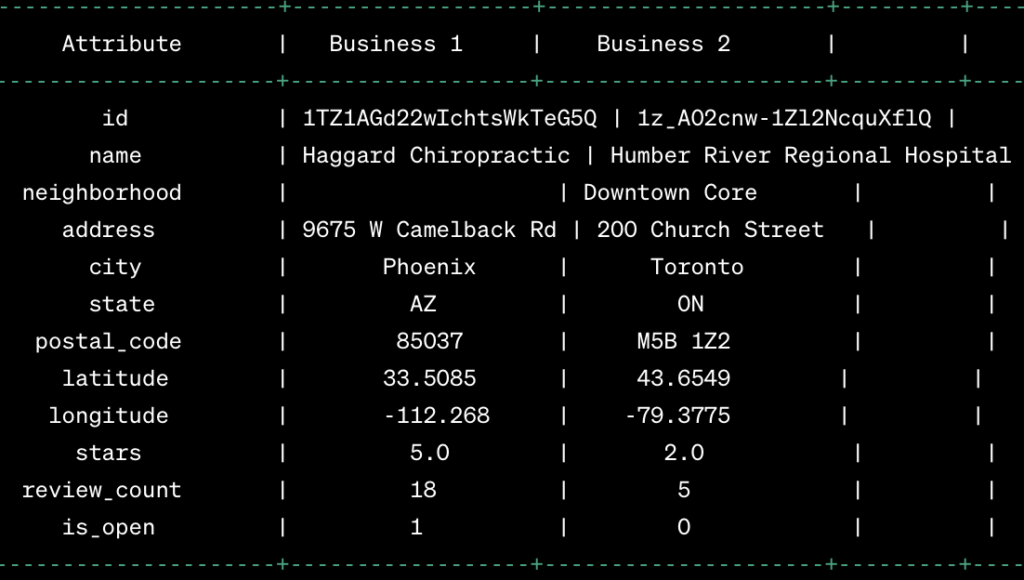
#i. ¿Do the two groups you chose to analyze have a different distribution of hours?
SELECT b.name, b.city, h.hours
FROM business b
JOIN hours h ON b.id = h.business_id
WHERE name = 'Haggard Chiropractic' OR name = 'Humber River Regional Hospital';
+----------------------+---------+---------------+
| name | city | hours |
+----------------------+---------+---------------+
| Haggard Cp.| Phoenix | Tuesday|15:00-19:00 |
| Haggard Cp.| Phoenix | Thursday|9:00-12:00 |
| Haggard Cp.| Phoenix | Wednesday|9:00-12:00 |
| Haggard Cp.| Phoenix | Monday|15:00-19:00 |
+----------------------+---------+---------------+
ANSWER: --The two business have different distribution of hours, mainly because Humber River Regional Hospital isn't open. On the table above we can see the time distribution of Haggard Chiropractic which has a several schedules; that could be one of the reason that they have a better rating.
#ii. ¿Do the two groups you chose to analyze have a different number of reviews?
ANSWER: --Yes, Haggard Chiropractic has 18 reviews and Humber River Regional Hospital has 5.
#iii. ¿Are you able to infer anything from the location data provided between these two groups? Explain.
ANSWER: --Phoenix is the capital of its state Arizona in the US. While Toronto is also the capital city of Ontario in Canada. Both cities are very populous and diverse, but one difference to point is that Phenix is well known for outdoor recreational opportunities. this can could relate with the need of more quality chiropracters in the zone, but further investigation would be needed to confirm this. On the other hand we don't have relevant data that points us to the reason on why Humber River Regional Hospital closed than it's low quality, because of low ratings. Further investigation on the web would be needed. 2) Group business based on the ones that are open and the ones that are closed.
¿What differences can you find between the ones that are still open and the ones that are closed? List at least two differences and the SQL code you used to arrive at your answer.
#SQL code used for analysis:
-- Open Businesses
SELECT AVG(avg_review_count) AS overall_avg_review_count,
AVG(avg_stars) AS overall_avg_stars,
SUM(UsefulFunnyCool) AS overall_UsefulFunnyCool
FROM (
SELECT b.name, b.is_open, AVG(b.review_count) AS avg_review_count, AVG(r.stars) AS avg_stars,
(SELECT SUM(r.useful) + SUM(r.funny) + SUM(r.cool)
FROM review
WHERE business_id = b.id) AS UsefulFunnyCool
FROM business b
JOIN review r ON b.id = r.business_id
WHERE b.is_open = 1
GROUP BY b.name, b.is_open
);
+--------------------------+-------------------+-------------------------+
| overall_avg_review_count | overall_avg_stars | overall_UsefulFunnyCool |
+--------------------------+-------------------+-------------------------+
| 193.024521073 | 3.74828133552 | 855 |
+--------------------------+-------------------+-------------------------+
-- Closed Businesses
SELECT AVG(avg_review_count) AS overall_avg_review_count,
AVG(avg_stars) AS overall_avg_stars,
SUM(UsefulFunnyCool) AS overall_UsefulFunnyCool
FROM (
SELECT b.name, b.is_open, AVG(b.review_count) AS avg_review_count, AVG(r.stars) AS avg_stars,
(SELECT SUM(r.useful) + SUM(r.funny) + SUM(r.cool)
FROM review
WHERE business_id = b.id) AS UsefulFunnyCool
FROM business b
JOIN review r ON b.id = r.business_id
WHERE b.is_open = 0
GROUP BY b.name, b.is_open
);
+--------------------------+-------------------+-------------------------+
| overall_avg_review_count | overall_avg_stars | overall_UsefulFunnyCool |
+--------------------------+-------------------+-------------------------+
| 103.606557377 | 3.65683060109 | 114 |
+--------------------------+-------------------+-------------------------+
#i. Difference 1:
-- Open businesses have a relevant difference of 89.42 more overall_avg_review_count.
#ii. Difference 2:
-- Open businesses have a small but still considerable advantage of 0.091 stars.
#iii. Difference 3:
-- Open business have a very big advantage in the overall of useful, funny and cool reviews, having 855, while the closed businesses have 114, this is a difference of 741 reviews. 3) For this last part of your analysis, you are going to choose the type of analysis you want to conduct on the Yelp dataset and are going to prepare the data for analysis.
– 1) Indicate the type of analysis you chose to do:
- Descriptive Analysis.
- Business Performance by Location: Analyze the distribution of businesses across different cities or regions and assess their performance based on ratings and review counts.
– 2) Write on the type of data you will need for your analysis and why you chose that data & iii. Output of your finished dataset & iv. Provide the SQL code you used to create your final dataset:
#1)Business Distribution by City: count of businesses in each city sorted in descending order.
SELECT city, COUNT(*) AS business_count
FROM business
GROUP BY city
ORDER BY business_count DESC;
+-----------------+----------------+
| city | business_count |
+-----------------+----------------+
| Las Vegas | 1561 |
| Phoenix | 1001 |
| Toronto | 985 |
| Scottsdale | 497 |
| Charlotte | 468 |
| Pittsburgh | 353 |
| Montréal | 337 |
| Mesa | 304 |
| Henderson | 274 |
| Tempe | 261 |
| Edinburgh | 239 |
| Chandler | 232 |
| Cleveland | 189 |
| Gilbert | 188 |
| Glendale | 188 |
| Madison | 176 |
| Mississauga | 150 |
| Stuttgart | 141 |
| Peoria | 105 |
| Markham | 80 |
| Champaign | 71 |
| North Las Vegas | 70 |
| North York | 64 |
| Surprise | 60 |
| Richmond Hill | 54 |
+-----------------+----------------+
(Output limit exceeded, 25 of 362 total rows shown)
#2)Business Performance by Ratings: get the avg rating and count of businesses in each city, sorted in desc order. This allows to asses performance of businesses in different cities based on rankings.
SELECT city, AVG(stars) AS average_rating, COUNT(*) AS business_count
FROM business
GROUP BY city
ORDER BY average_rating DESC;
+------------------+----------------+----------------+
| city | average_rating | business_count |
+------------------+----------------+----------------+
| Ahwahtukee | 5.0 | 1 |
| Broadlands | 5.0 | 1 |
| Brooklin | 5.0 | 1 |
| Dane | 5.0 | 1 |
| De Forest | 5.0 | 1 |
| East Gwillimbury | 5.0 | 1 |
| Freyburg | 5.0 | 2 |
| Garfield Heights | 5.0 | 2 |
| Glenshaw | 5.0 | 1 |
| Houston | 5.0 | 1 |
| Kennedy Township | 5.0 | 1 |
| L'ile-Bizard | 5.0 | 1 |
| McFarland | 5.0 | 1 |
| Olmsted Township | 5.0 | 1 |
| Repentigny | 5.0 | 1 |
| St-Eugène | 5.0 | 1 |
| Sunnyslope | 5.0 | 1 |
| Terrebonne | 5.0 | 1 |
| University Ht | 5.0 | 1 |
| Waddell | 4.75 | 2 |
| Youngtown | 4.75 | 2 |
| Ambridge | 4.5 | 3 |
| Berry | 4.5 | 1 |
| Caledon | 4.5 | 1 |
| Chardon | 4.5 | 2 |
+------------------+----------------+----------------+
(Output limit exceeded, 25 of 362 total rows shown)
#2.1) As an extra I want to know the behavior of the top 20 cities with the most businesses in relation to the avg.rating.
SELECT city, AVG(stars) AS average_rating, COUNT(*) AS business_count
FROM business
GROUP BY city
HAVING COUNT(*) >= 50
ORDER BY business_count DESC
LIMIT 20;
+-------------+----------------+----------------+
| city | average_rating | business_count |
+-------------+----------------+----------------+
| Las Vegas | 3.74311338885 | 1561 |
| Phoenix | 3.63986013986 | 1001 |
| Toronto | 3.54568527919 | 985 |
| Scottsdale | 3.95674044266 | 497 |
| Charlotte | 3.57478632479 | 468 |
| Pittsburgh | 3.80311614731 | 353 |
| Montréal | 3.6646884273 | 337 |
| Mesa | 3.59868421053 | 304 |
| Henderson | 3.73357664234 | 274 |
| Tempe | 3.72413793103 | 261 |
| Edinburgh | 3.79916317992 | 239 |
| Chandler | 3.6724137931 | 232 |
| Cleveland | 3.65873015873 | 189 |
| Gilbert | 3.86170212766 | 188 |
| Glendale | 3.54521276596 | 188 |
| Madison | 3.68465909091 | 176 |
| Mississauga | 3.42333333333 | 150 |
| Stuttgart | 3.81205673759 | 141 |
| Peoria | 3.78571428571 | 105 |
| Markham | 3.28125 | 80 |
+-------------+----------------+----------------+
#3)Business Performance by Review Counts: calculation for avg review_count and count of businesses in each city, sorted in DESC order. This query helps to understand the popularity and engagement of businesses in different cities based on number of reviews they recieve.
SELECT city, AVG(review_count) AS avg_review_count, COUNT(*) AS business_count
FROM business
GROUP BY city
ORDER BY avg_review_count DESC;
+------------------------+------------------+----------------+
| city | avg_review_count | business_count |
+------------------------+------------------+----------------+
| Woodmere Village | 242.0 | 1 |
| Mount Lebanon | 138.0 | 1 |
| Ahwatukee | 117.5 | 2 |
| Oakmont | 105.5 | 2 |
| Enterprise | 89.0 | 1 |
| Davidson | 78.5 | 2 |
| Munroe Falls | 74.0 | 1 |
| McMurray | 58.0 | 2 |
| Las Vegas | 53.0775144138 | 1561 |
| Whitchurch-Stouffville | 52.0 | 1 |
| Windsor | 50.0 | 1 |
| Lakewood | 45.78125 | 32 |
| Homestead | 44.3333333333 | 12 |
| Summerlin | 44.0 | 1 |
| Turtle Creek | 44.0 | 2 |
| El Mirage | 43.4 | 5 |
| Peninsula | 42.0 | 1 |
| Scottsdale | 41.476861167 | 497 |
| Paradise Valley | 40.8333333333 | 6 |
| Tempe | 40.245210728 | 261 |
| Dormont | 40.0 | 1 |
| nboulder city | 40.0 | 1 |
| Henderson | 39.6751824818 | 274 |
| Seven Hills | 35.0 | 3 |
| Chandler | 34.9655172414 | 232 |
+------------------------+------------------+----------------+
(Output limit exceeded, 25 of 362 total rows shown)